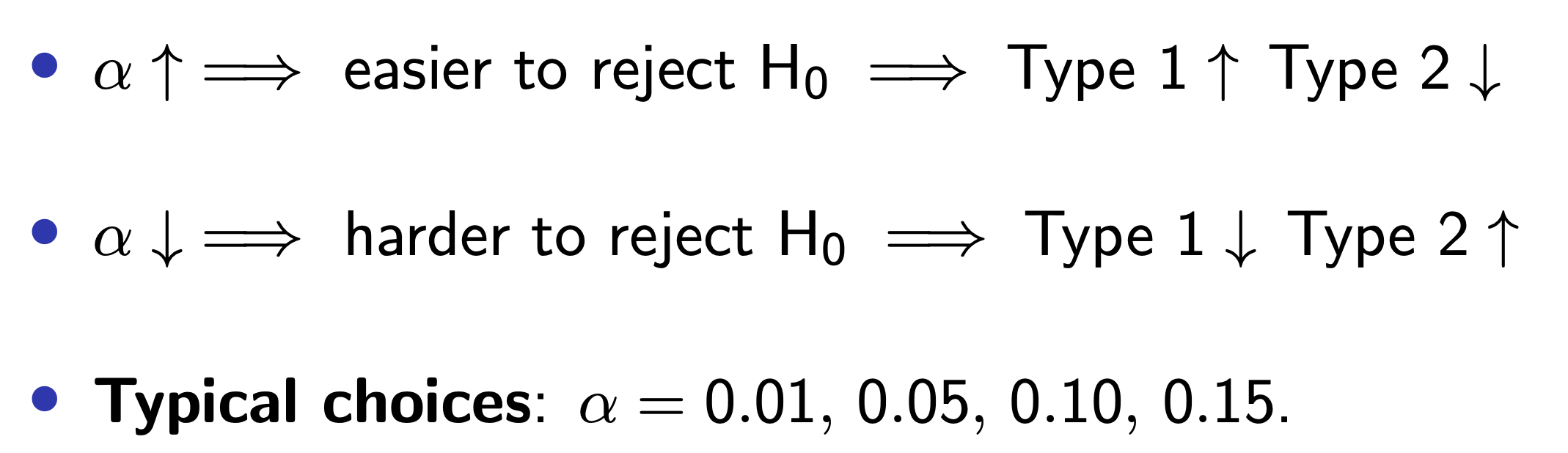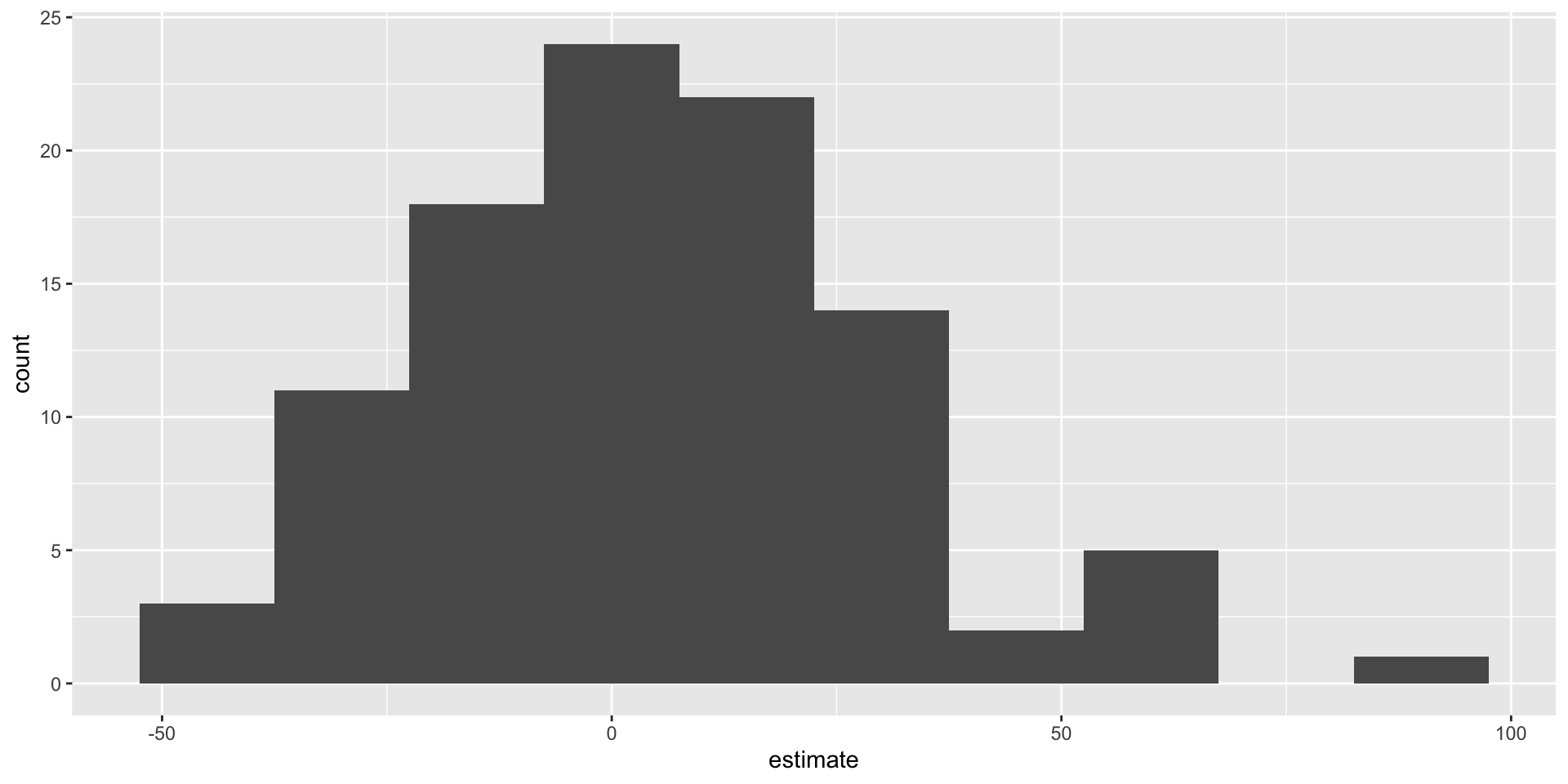
# A tibble: 2 × 2
term estimate
<chr> <dbl>
1 (Intercept) 2.94
2 log_inc 0.657Lecture 20
2025-04-03
# A tibble: 2 × 2
term estimate
<chr> <dbl>
1 (Intercept) 2.94
2 log_inc 0.657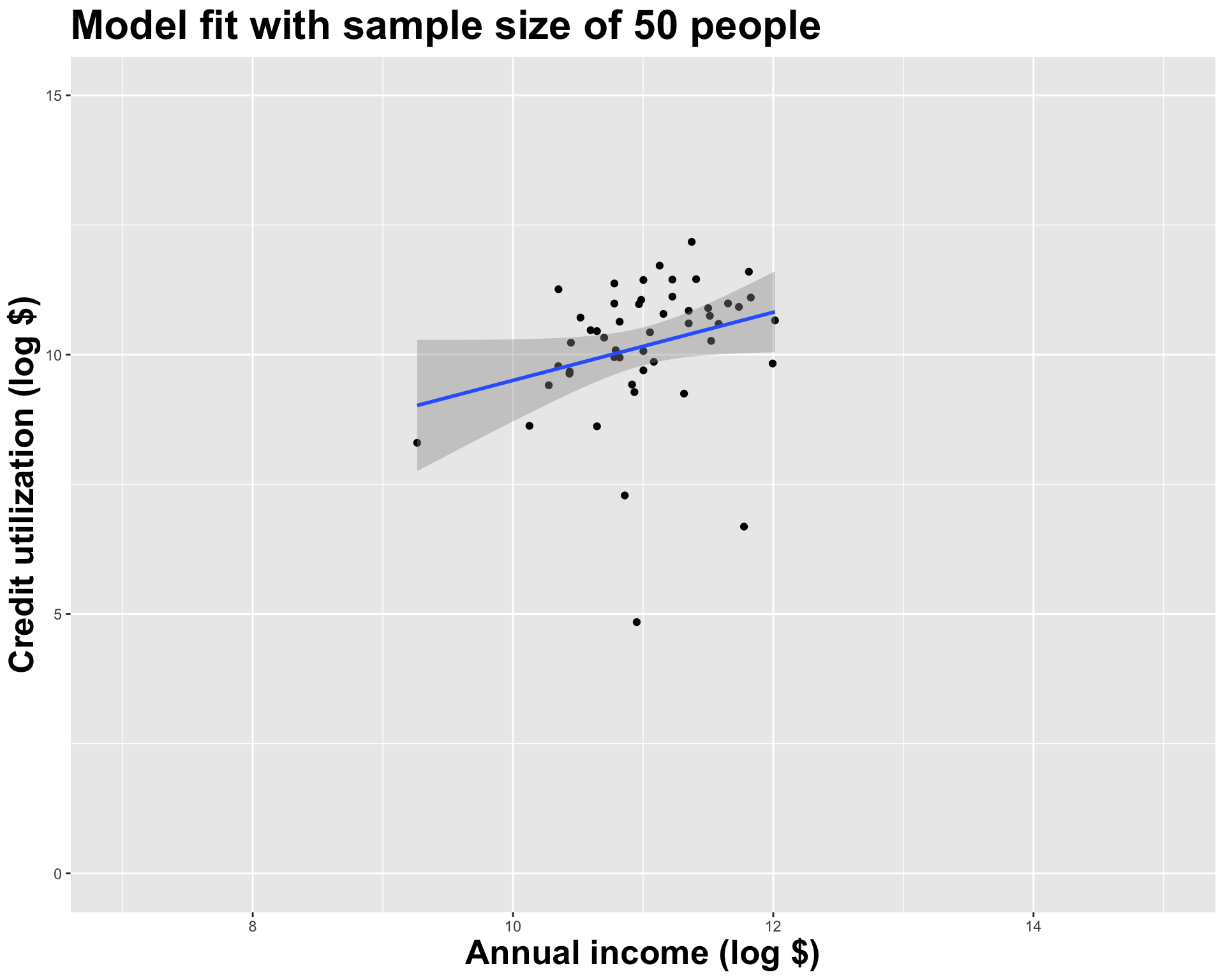
# A tibble: 2 × 2
term estimate
<chr> <dbl>
1 (Intercept) 5.29
2 log_inc 0.486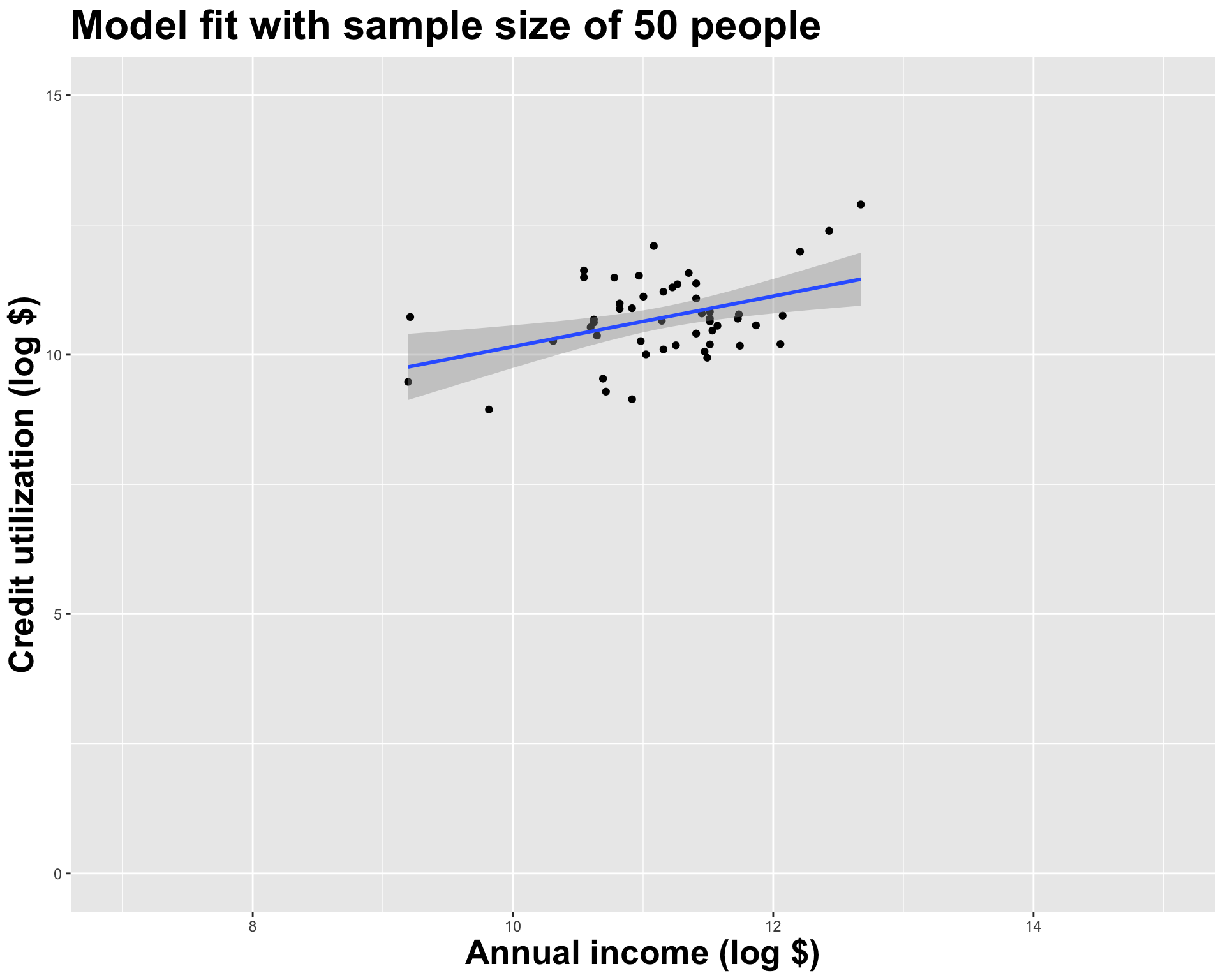
# A tibble: 2 × 2
term estimate
<chr> <dbl>
1 (Intercept) 1.62
2 log_inc 0.805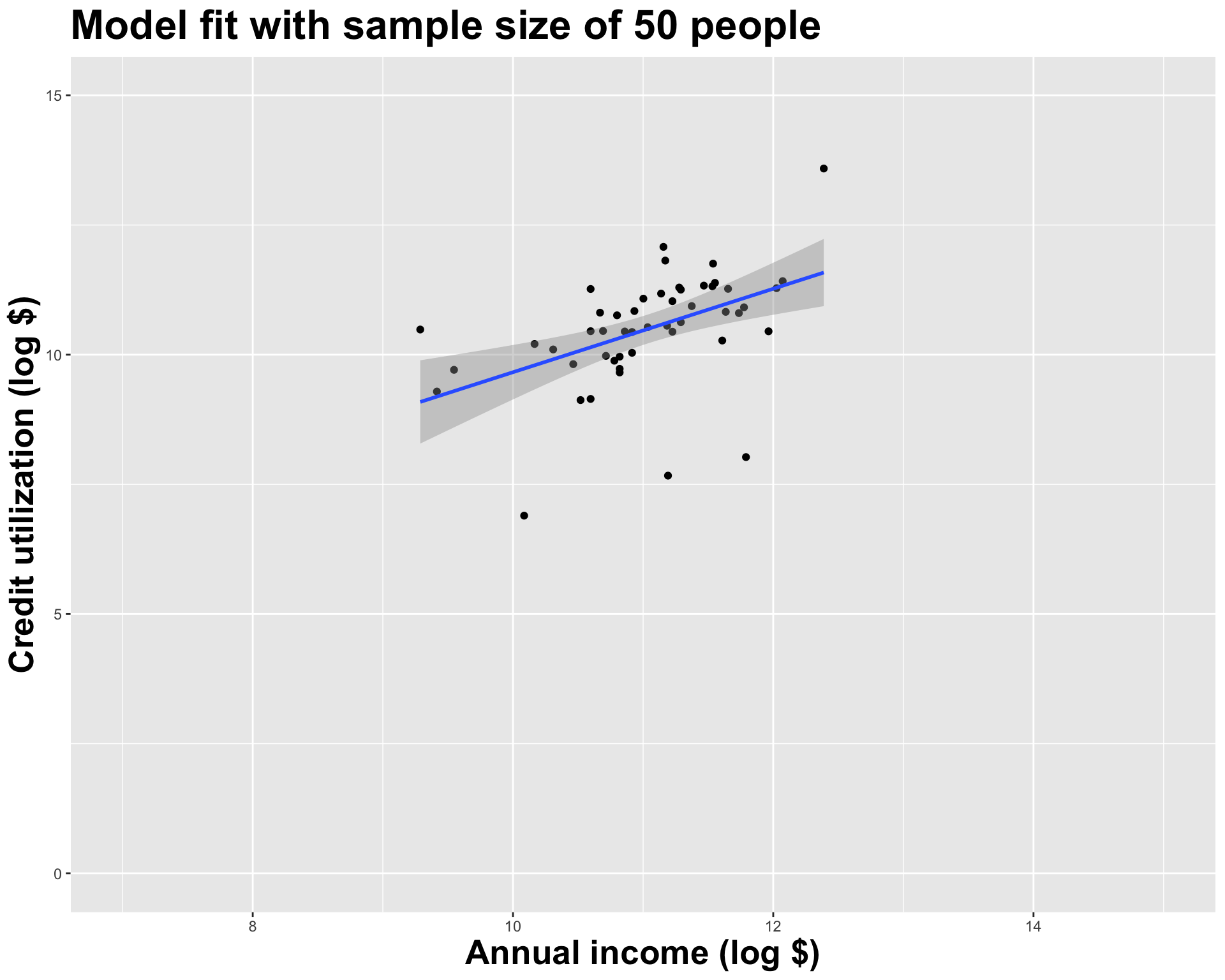
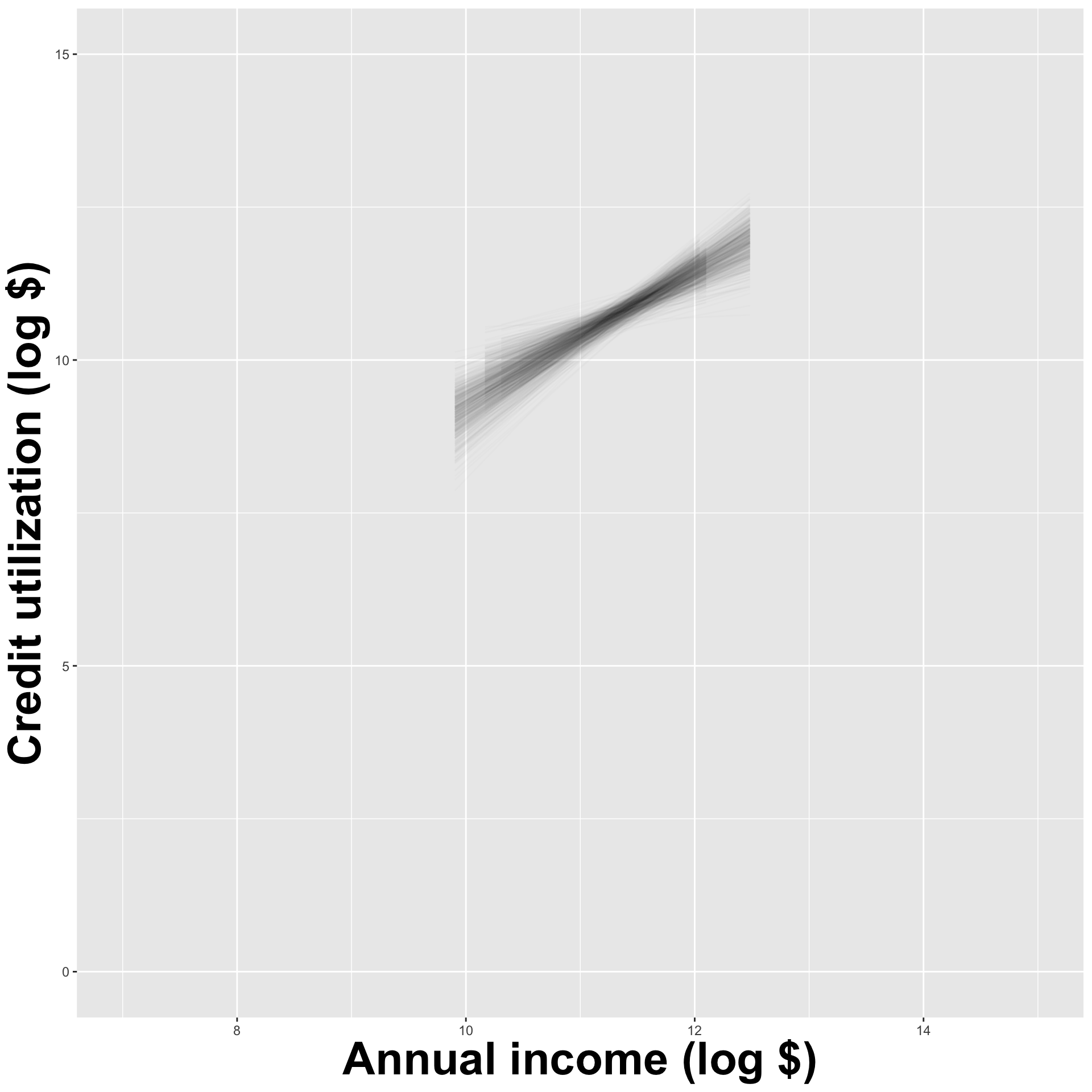
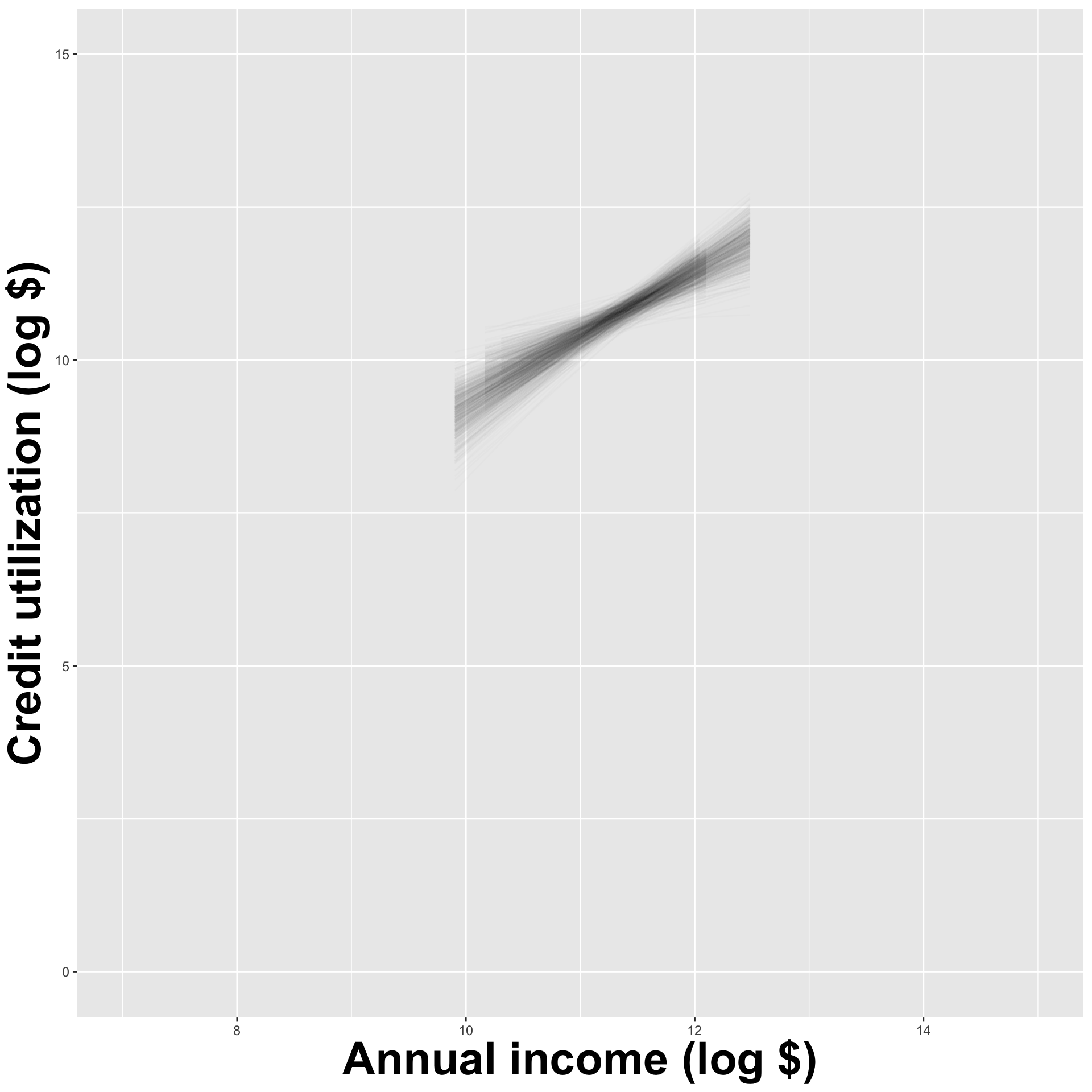
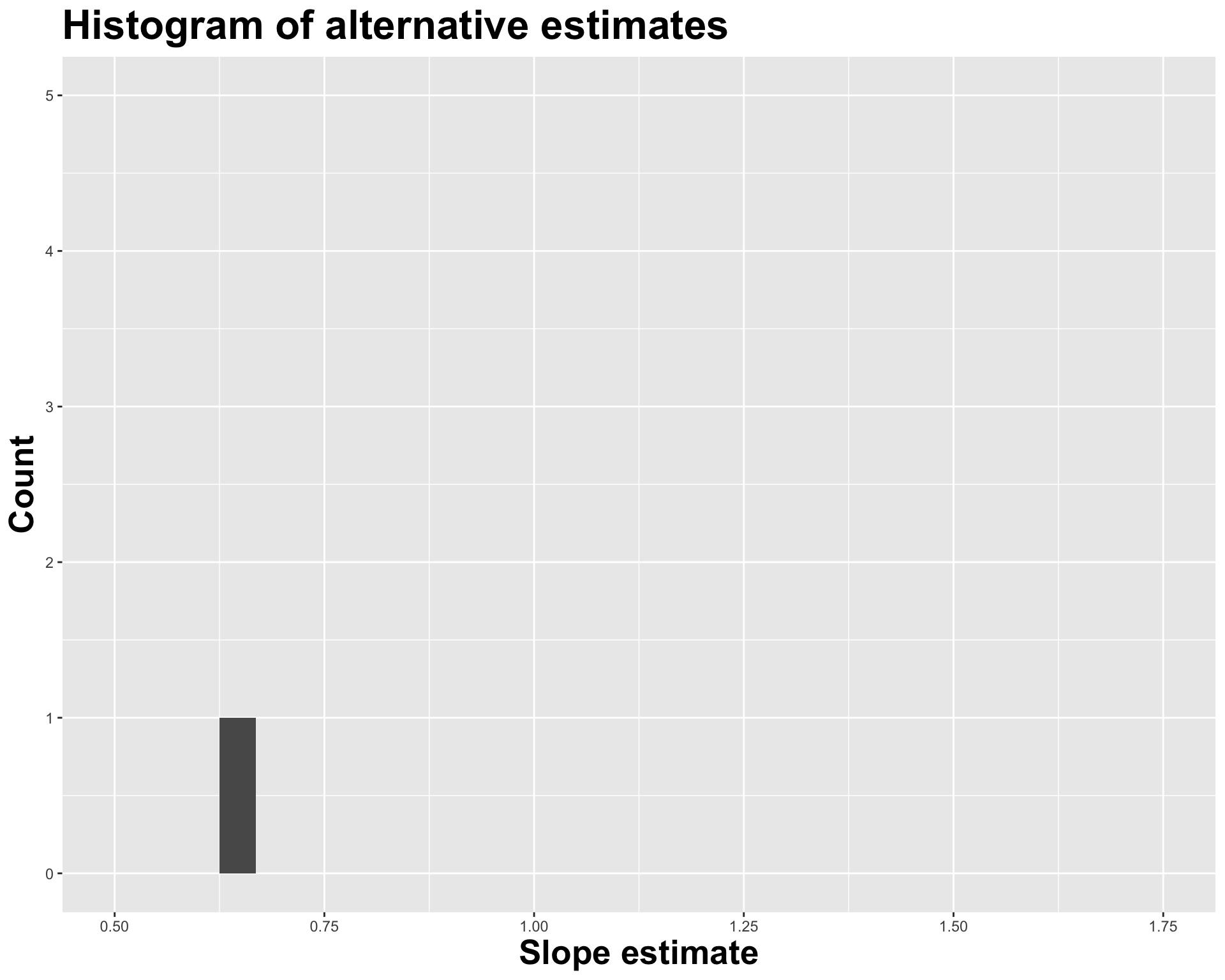
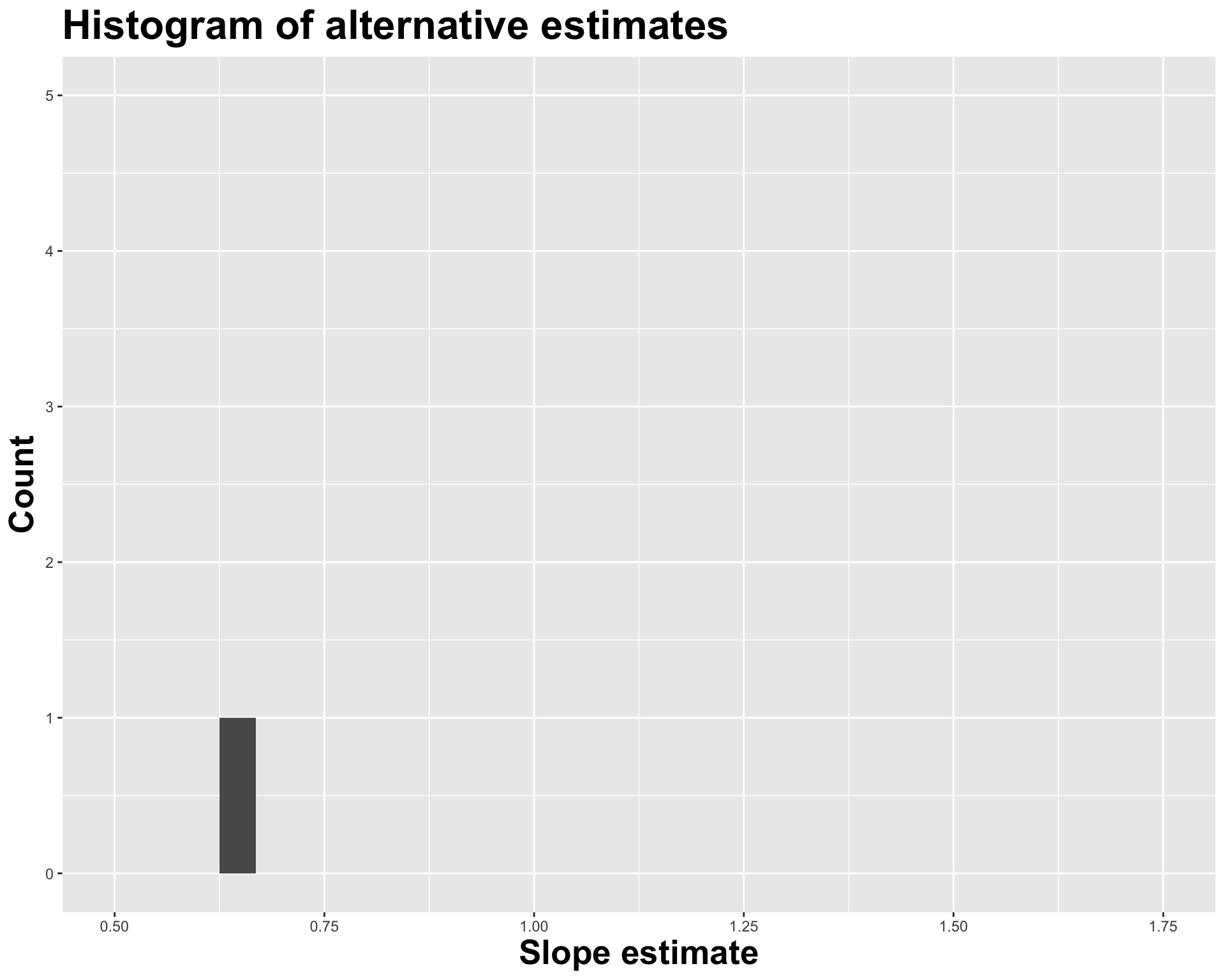
How sensitive are the estimates to the data they are based on?
- Very? Then uncertainty is high, results are unreliable;
- Not very? Uncertainty is low, results are more reliable.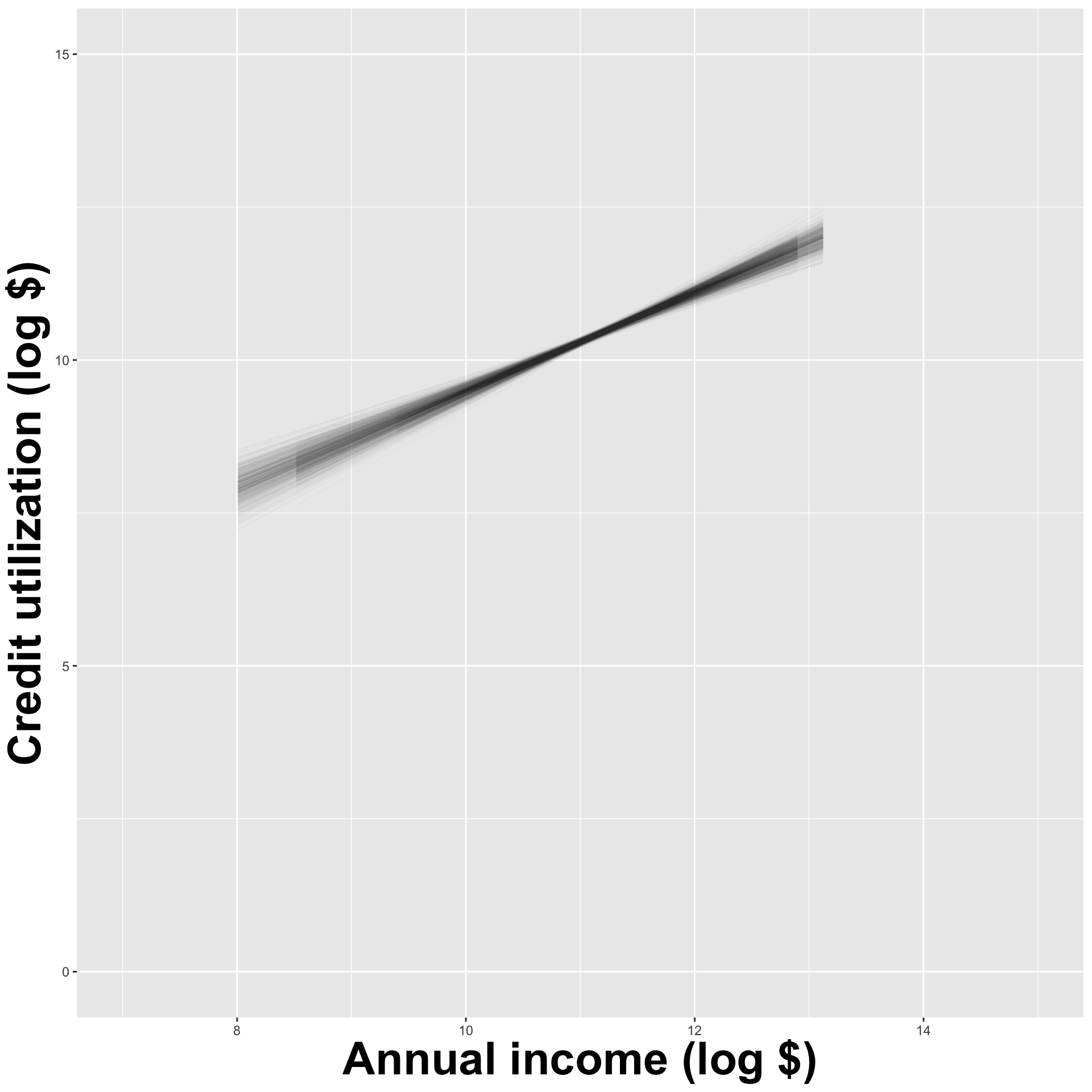
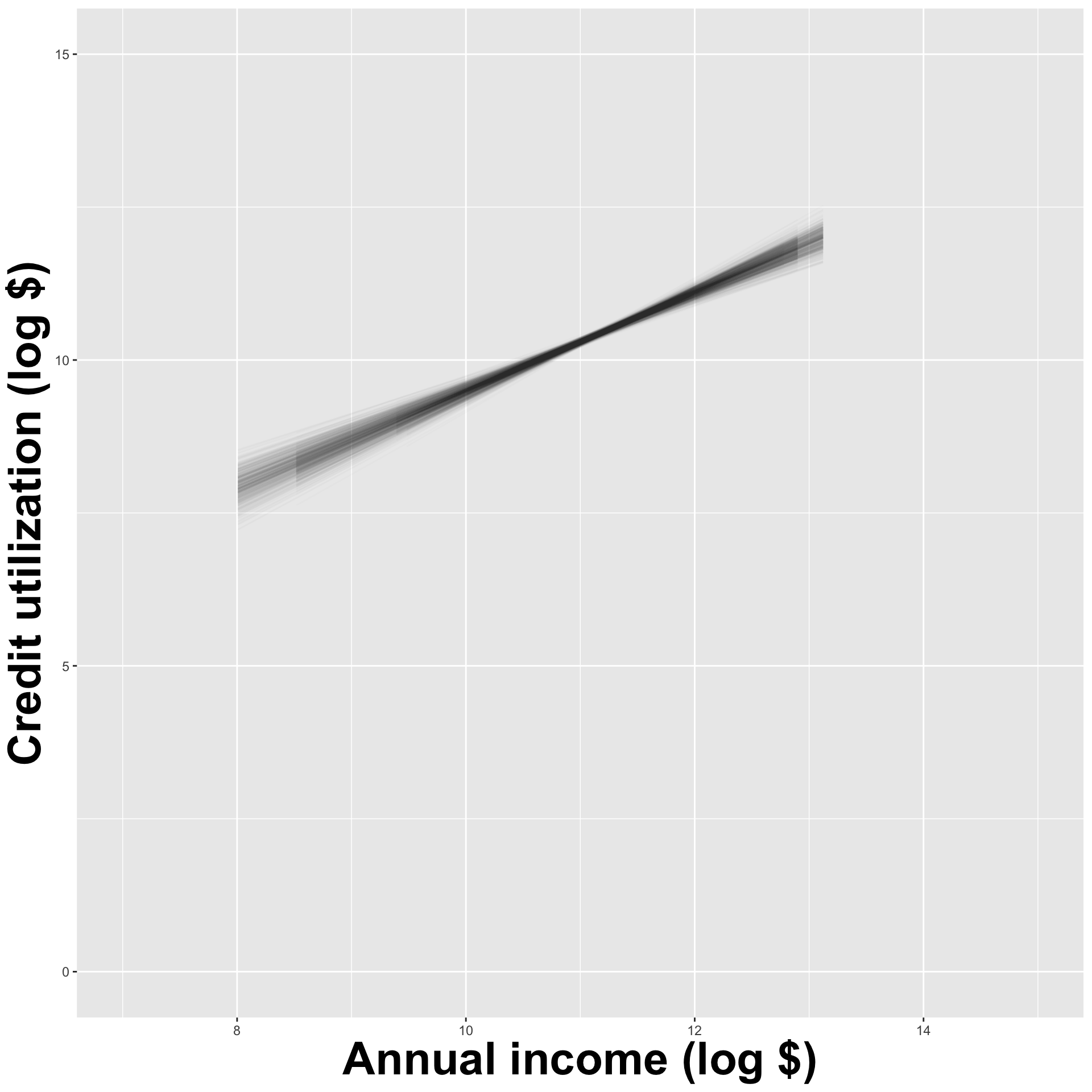

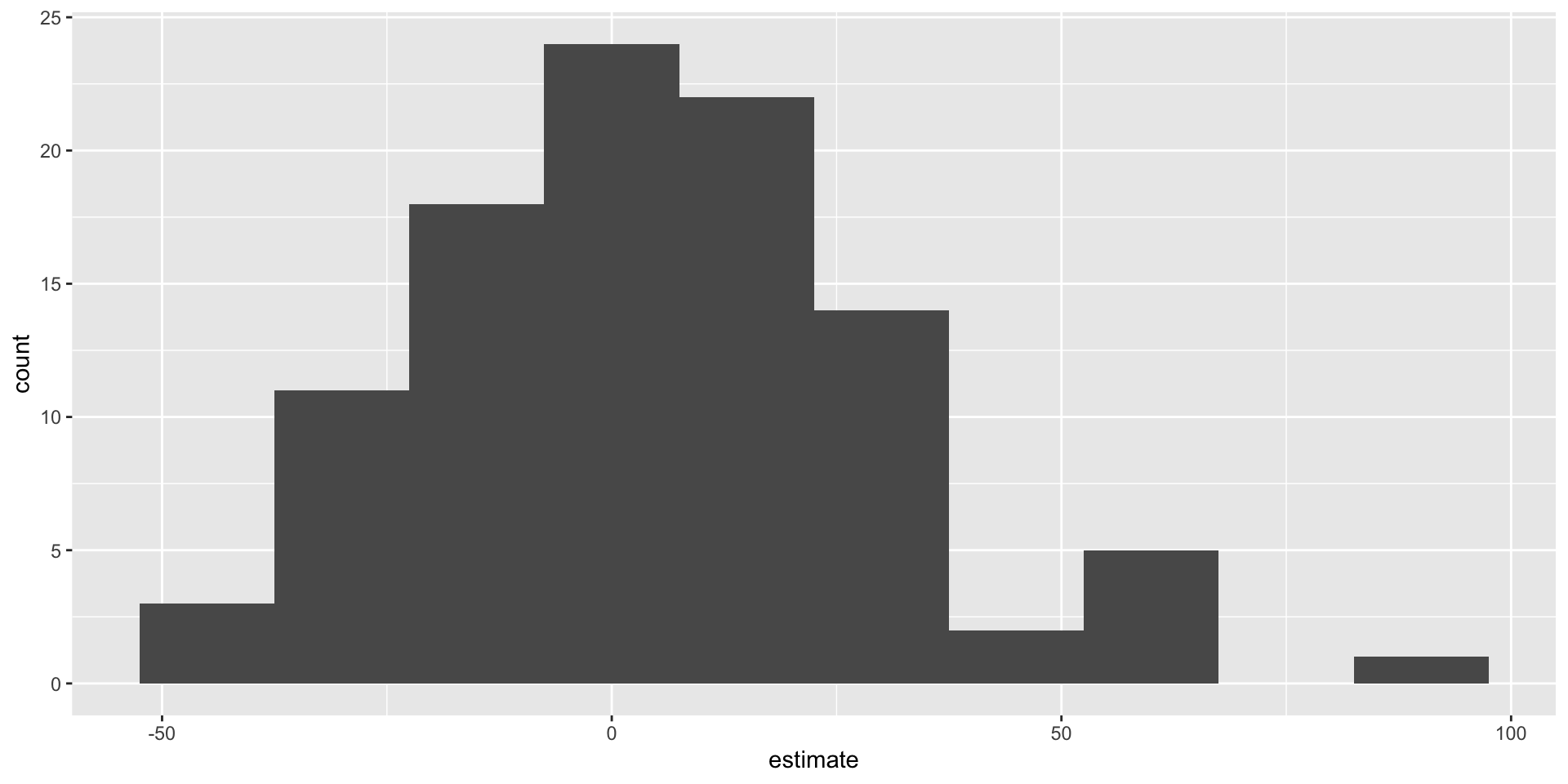
openintro::duke_forest

Goal: Use the area (in square feet) to understand variability in the price of houses in Duke Forest.
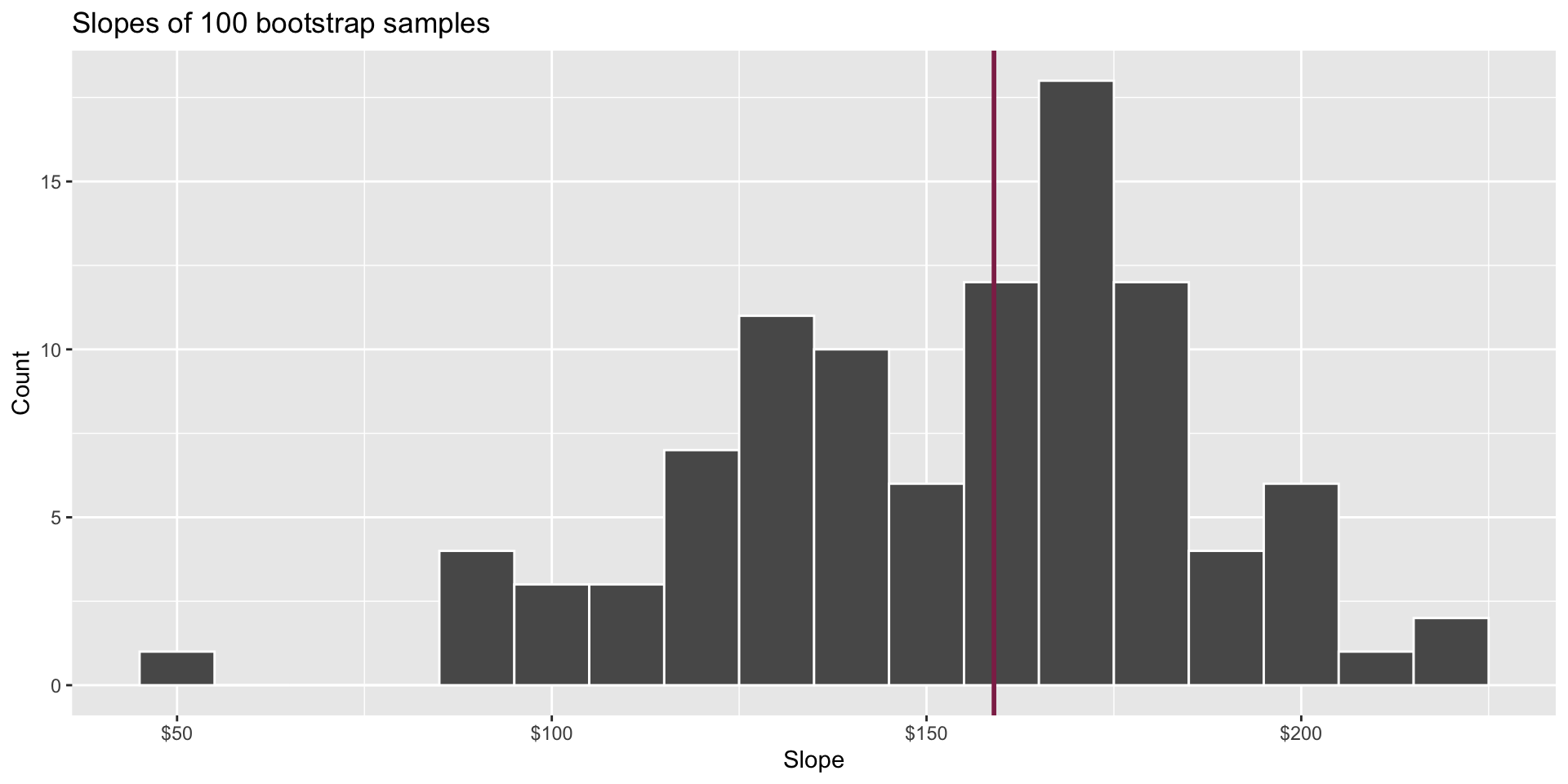
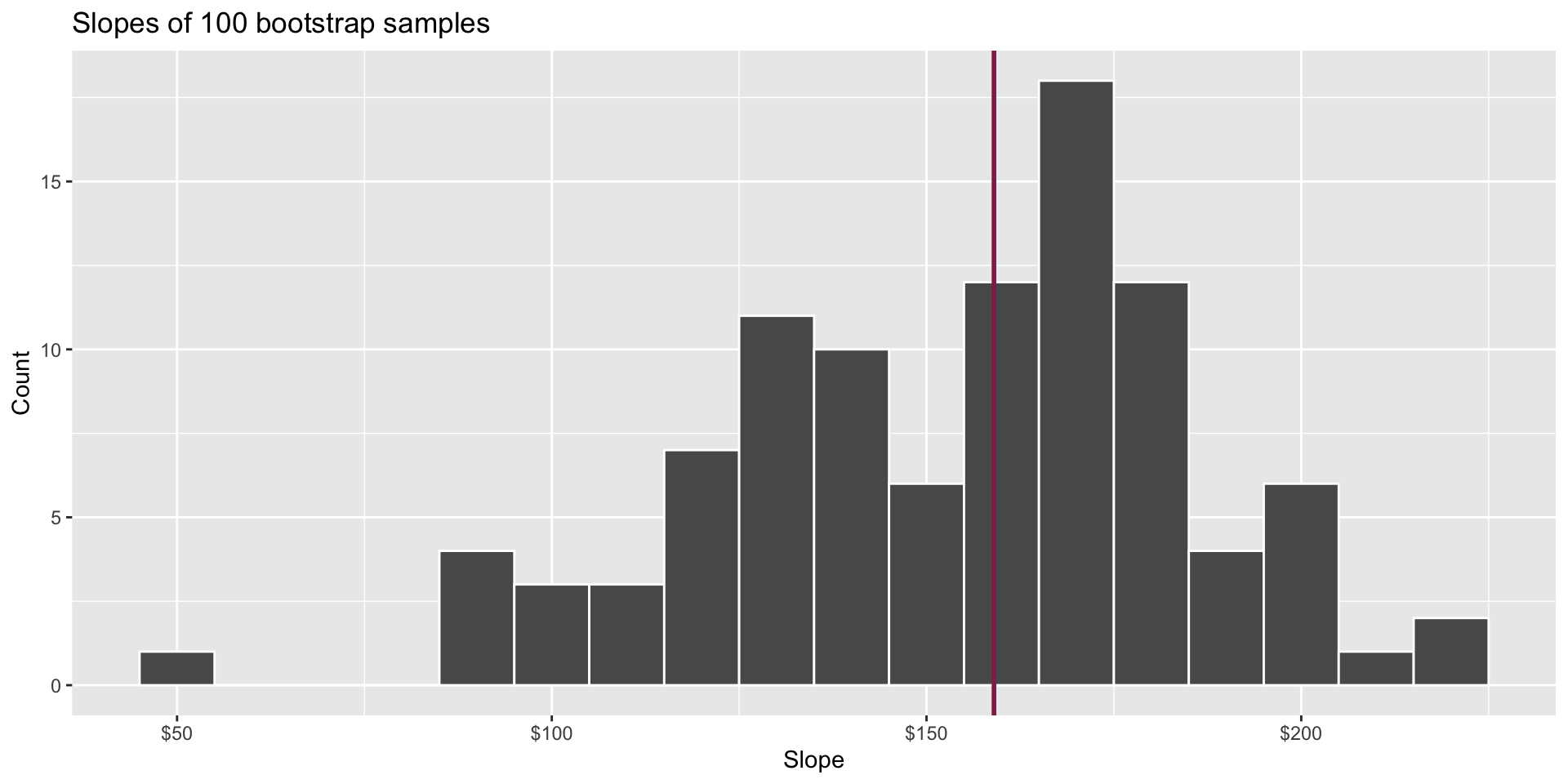
Fill in the blank: For each additional square foot, the model predicts the sale price of Duke Forest houses to be higher, on average, by $159, plus or minus ___ dollars.
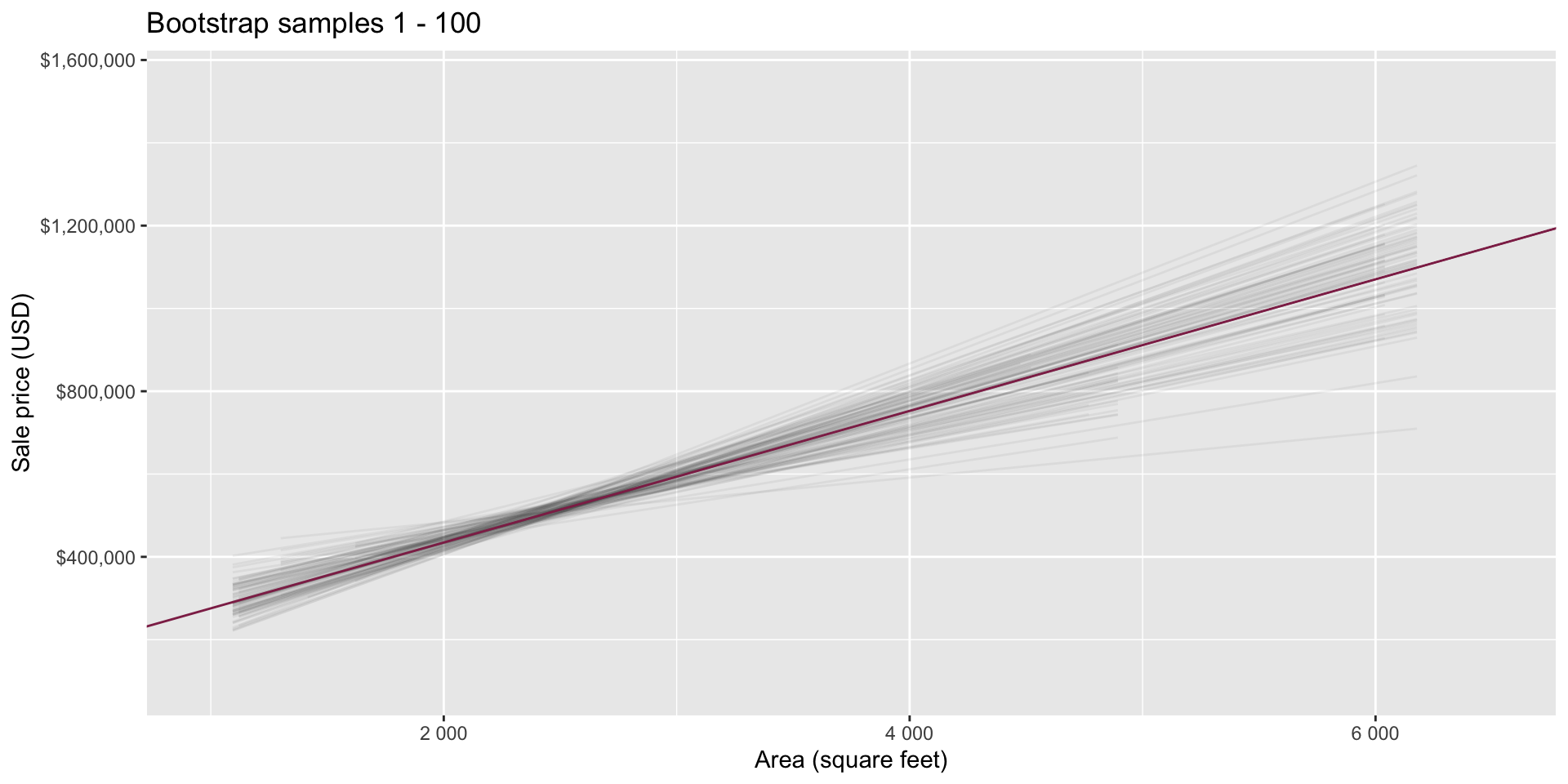
Fill in the blank: For each additional square foot, we expect the sale price of Duke Forest houses to be higher, on average, by $159, plus or minus ___ dollars.
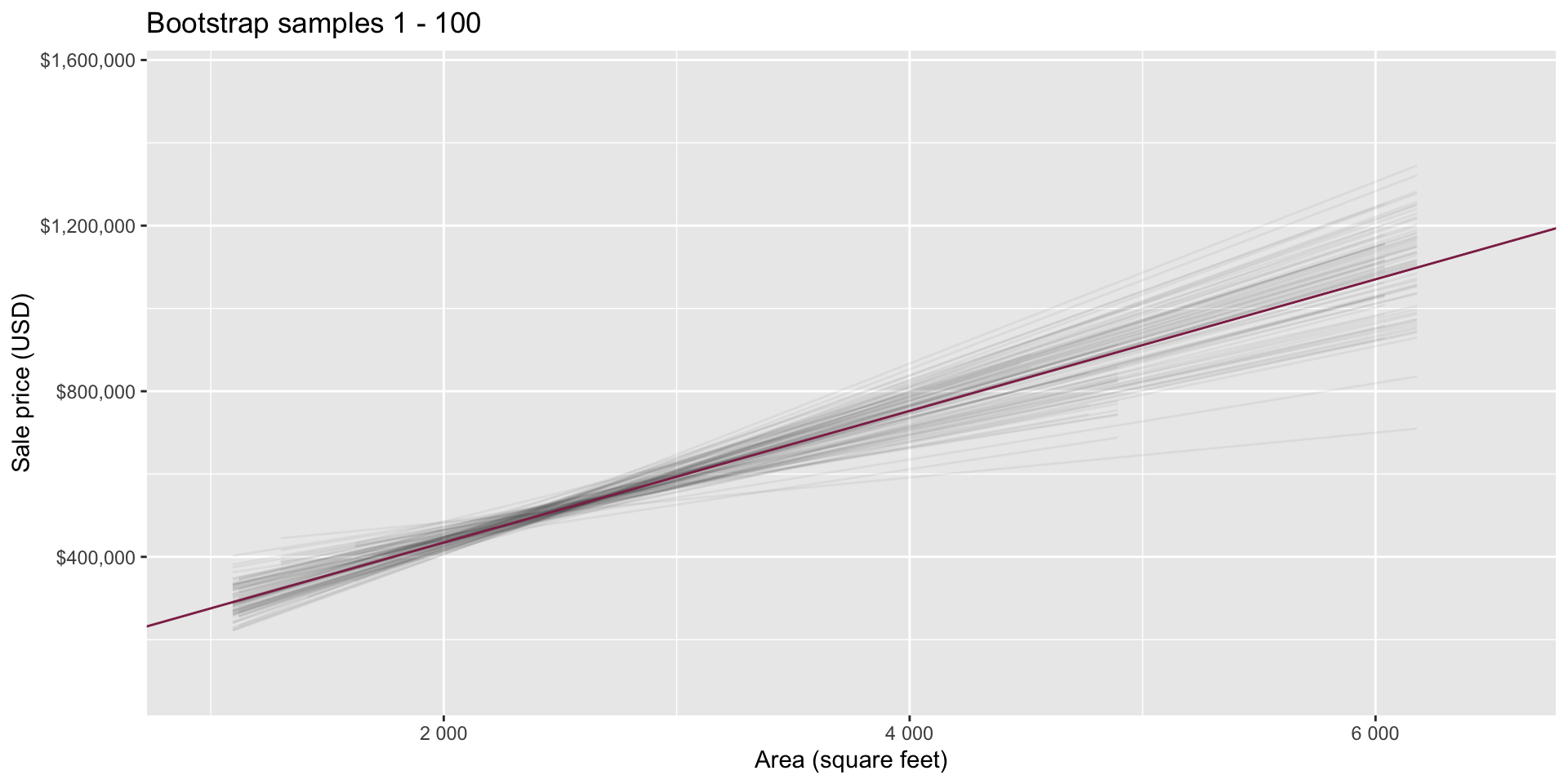
How confident are you that the true slope is between $0 and $250? How about $150 and $170? How about $90 and $210?

\(H_0\) person innocent vs \(H_A\) person guilty

\(H_0\) person well vs \(H_A\) person sick.

Pick a threshold \(\alpha\in[0,\,1]\) called the discernibility level and threshold the \(p\)-value: