Go to the course organization at github.com/sta199-s25 organization on GitHub. Click on the repo with the prefix lab-4.
Click on the green CODE button and select Use SSH. Click on the clipboard icon to copy the repo URL.
In RStudio, go to File ➛ New Project ➛Version Control ➛ Git to clone your Lab 4 repo.
Update the YAML
In lab-4.qmd, update the author field to your name, Render your document, and examine the changes. Then, in the Git pane, click on Diff to view your changes, add a commit message (e.g., “Added author name”), and click Commit. Then, Push the changes to your GitHub repository and, in your browser, confirm that these changes have indeed propagated to your repository.
mutate(): modifies existing data frame – creates new columns (i.e., variables) or modifies existing columns. Note that the number of rows does not change.
summarize(): creates a new data frame – returns one for for each combination of grouping variables. If there is no grouping it will have a single row summarizing all observations
Example: Set up
library(tidyverse)library(knitr)df <-tibble(col_1 =c("A", "A", "A", "B", "B"),col_2 =c("X", "Y", "X", "X", "Y"),col_3 =c(1, 2, 3, 4, 5))df #this is used to display the data frame
# A tibble: 5 × 3
col_1 col_2 col_3
<chr> <chr> <dbl>
1 A X 1
2 A Y 2
3 A X 3
4 B X 4
5 B Y 5
What would be the result of the following code? # rows? # cols? column/variable names?
# A tibble: 5 × 4
col_1 col_2 col_3 med_col_3
<chr> <chr> <dbl> <dbl>
1 A X 1 3
2 A Y 2 3
3 A X 3 3
4 B X 4 3
5 B Y 5 3
summarize()
df |>summarize(med_col_3 =median(col_3))
# A tibble: 1 × 1
med_col_3
<dbl>
1 3
We did not assign any new or existing data frames (e.g., no ??? <-). In particular, we did not write over df (i.e., no df <-), so what will be the result of the following code?
df
Example: assignment
It’s the same as when it was originally assigned. It has not been overwritten!
df
# A tibble: 5 × 3
col_1 col_2 col_3
<chr> <chr> <dbl>
1 A X 1
2 A Y 2
3 A X 3
4 B X 4
5 B Y 5
We will often write a single pipeline and show the result, i.e., no assignment.
If you will need to refer to the data frame later, it might be a good idea to assign a name to the data frame. Otherwise, see the result and continue on.
Note: if you assign the new/updated data frame, the result does not appear in the Console or the rendered document! (Type the name of the variable, e.g., df as shown above, to display the data frame.)
Example: with groups
What if there is grouping?
# group by 1 variabledf |>group_by(col_1) |>mutate(med_col_3 =median(col_3))df |>group_by(col_1) |>summarize(med_col_3 =median(col_3))# group by 2 variablesdf |>group_by(col_1, col_2) |>mutate(med_col_3 =median(col_3))df |>group_by(col_1, col_2) |>summarize(med_col_3 =median(col_3))
If you aren’t sure, try it out and see what happens (e.g., use data frame from Lab 3, Part 1).
pivot_*()
Pivoting reshapes the data frame.
pivot_longer makes the updated data frame longer (i.e., fewer columns)
pivot_wider makes the updated data frame wider (i.e., more columns)
Example: pivot_*()
Let’s examine the number of hours people slept during the week.
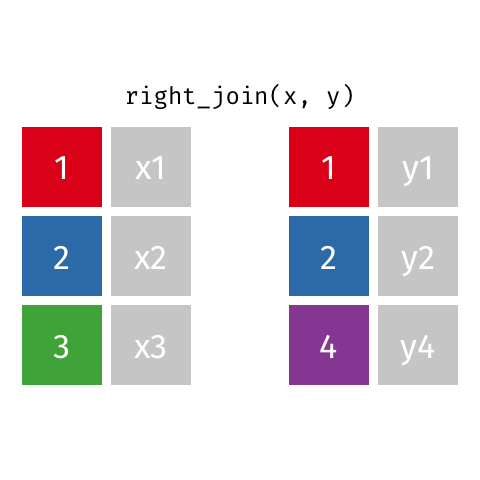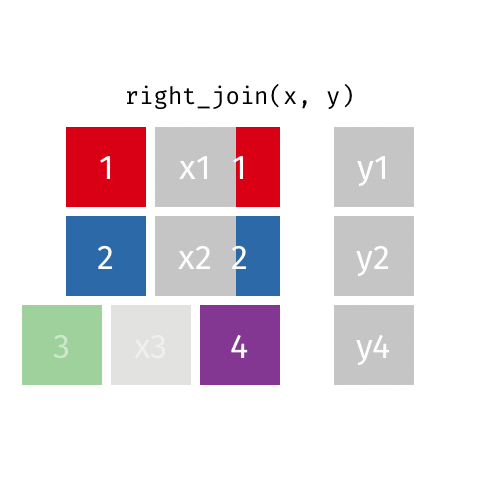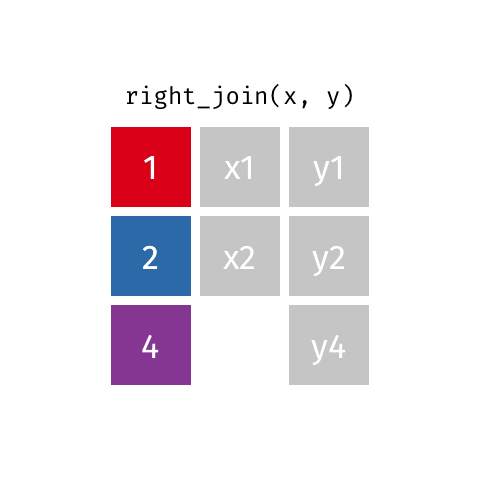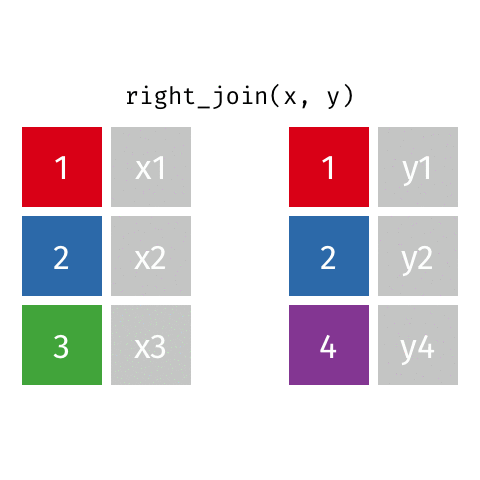
Typically we use *_join() to merge data from two data frames (e.g., left_join(), right_join(), full_join(), inner_join()), i.e., create a new data frames with more columns/variables.
For example, there is useful info in two data frames: x and y. We want to create a new data frame which includes variables from both (e.g., data frame x has student ID numbers and student names and data frame y has student ID numbers and email addresses).
Sometimes we use *_join() to filter rows/observations, e.g., find the rows from one data frame that do (or do not) exist in another data frame (e.g., semi_join(), anti_join())
Let’s focus on the joins that merge data…
Example: *_join() setup
For the next few slides…
x <-tibble(id =c(1, 2, 3),value_x =c("x1", "x2", "x3") )x
# A tibble: 3 × 2
id value_x
<dbl> <chr>
1 1 x1
2 2 x2
3 3 x3
y <-tibble(id =c(1, 2, 4),value_y =c("y1", "y2", "y4") )y
# A tibble: 3 × 2
id value_y
<dbl> <chr>
1 1 y1
2 2 y2
3 4 y4
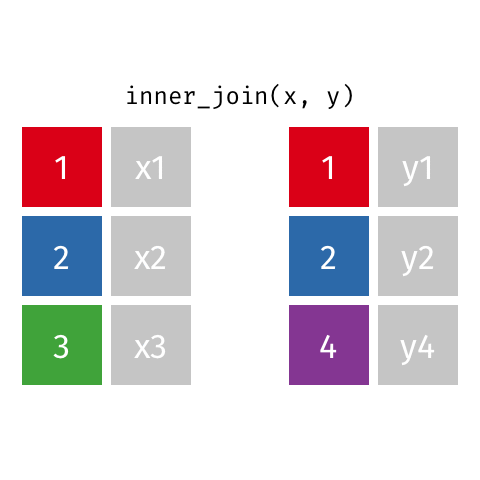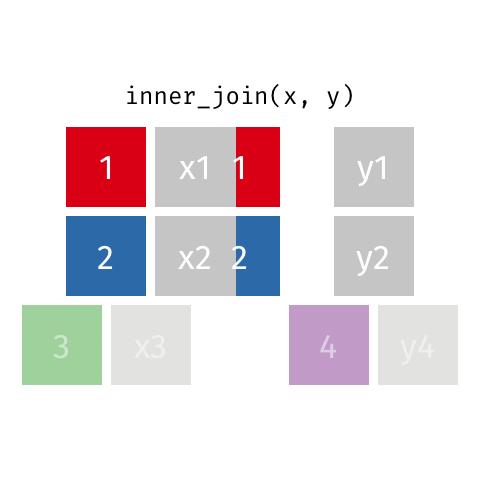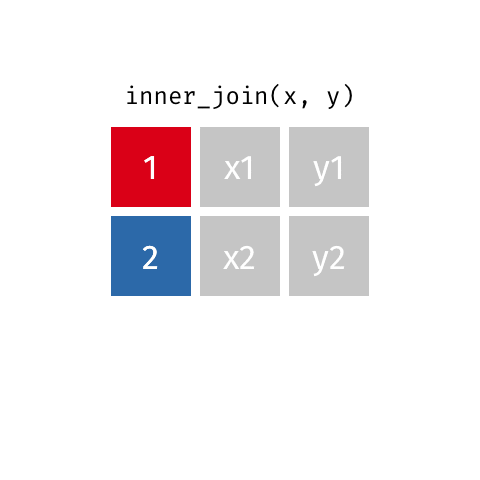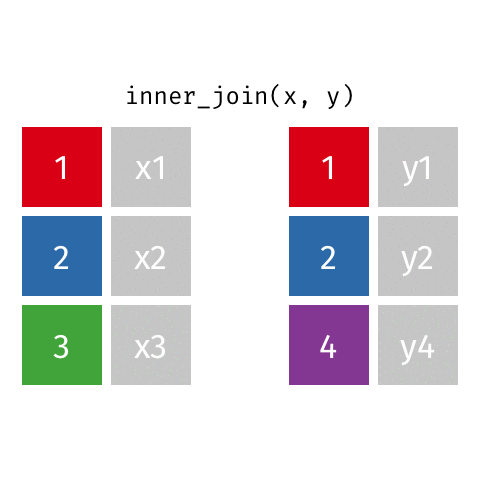
# A tibble: 2 × 3
id value_x value_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
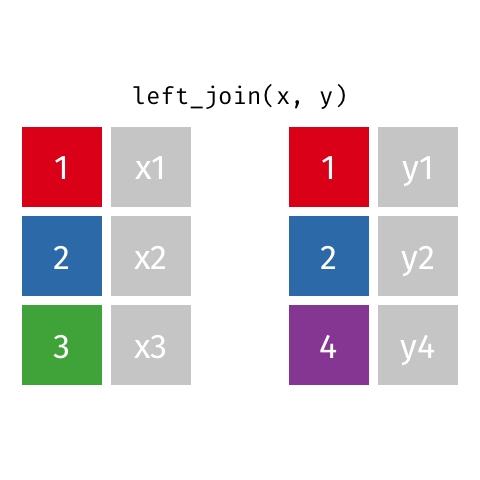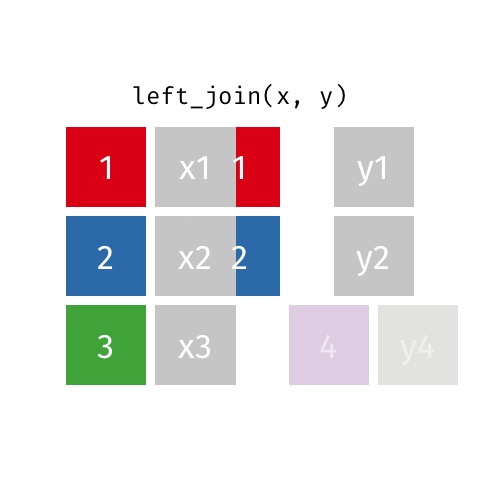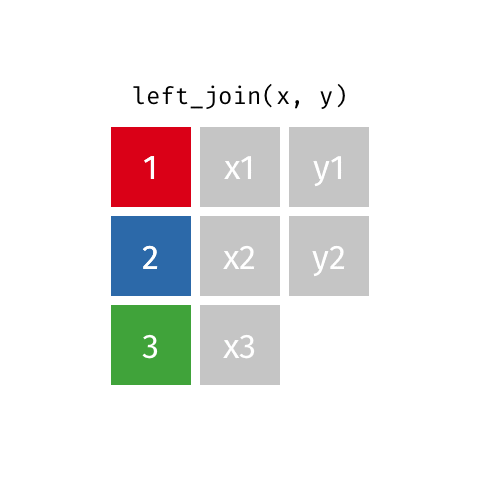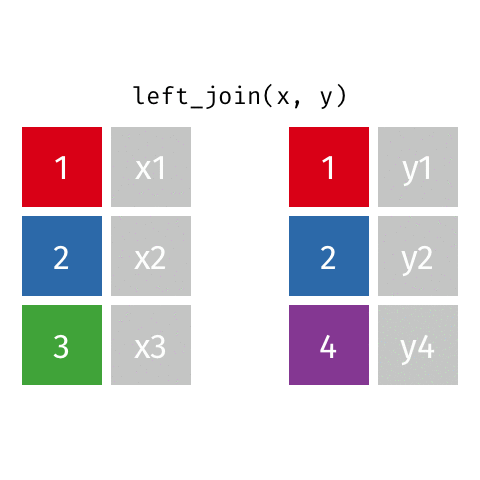
Keep all rows that exist in both data frames.
Example: *_join() more info
We could also use *_join() within a pipeline.
x |>left_join(y)
Which data frame is on the left and which is on the right? x or y?
The above code is equivalent to left_join(x, y) since the result before the pipe |> is passed as the first argument to the function after the pipe.
In this example x has 2 variables: id and value_x and y has 2 variables: id and value_x, so there was only one common variable between x and y – id. We could have been more explicit and used the following code
left_join(x, y, by =join_by(id))# or alternativelyleft_join(x, y, by =join_by(id == id))
Factors
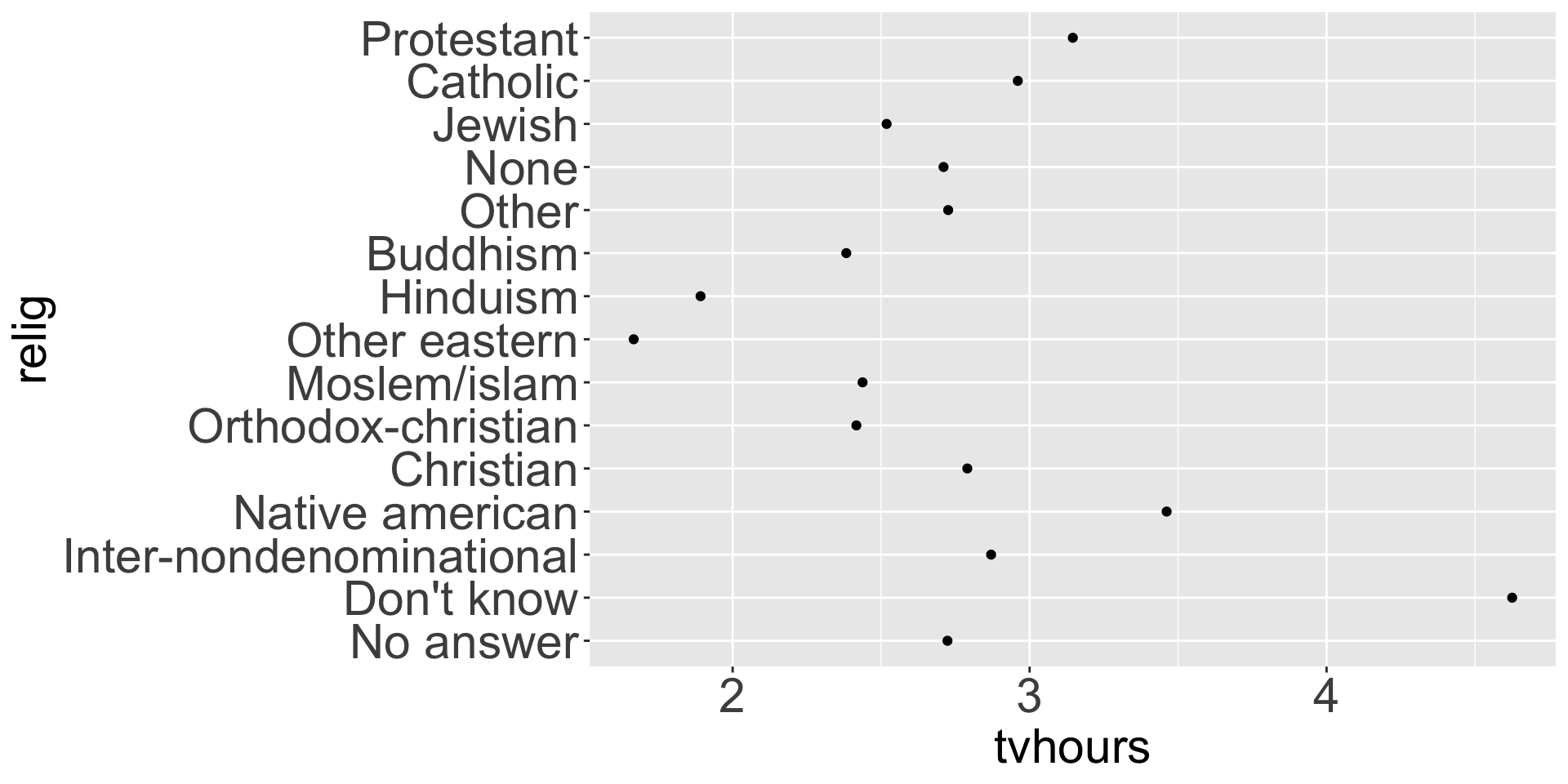
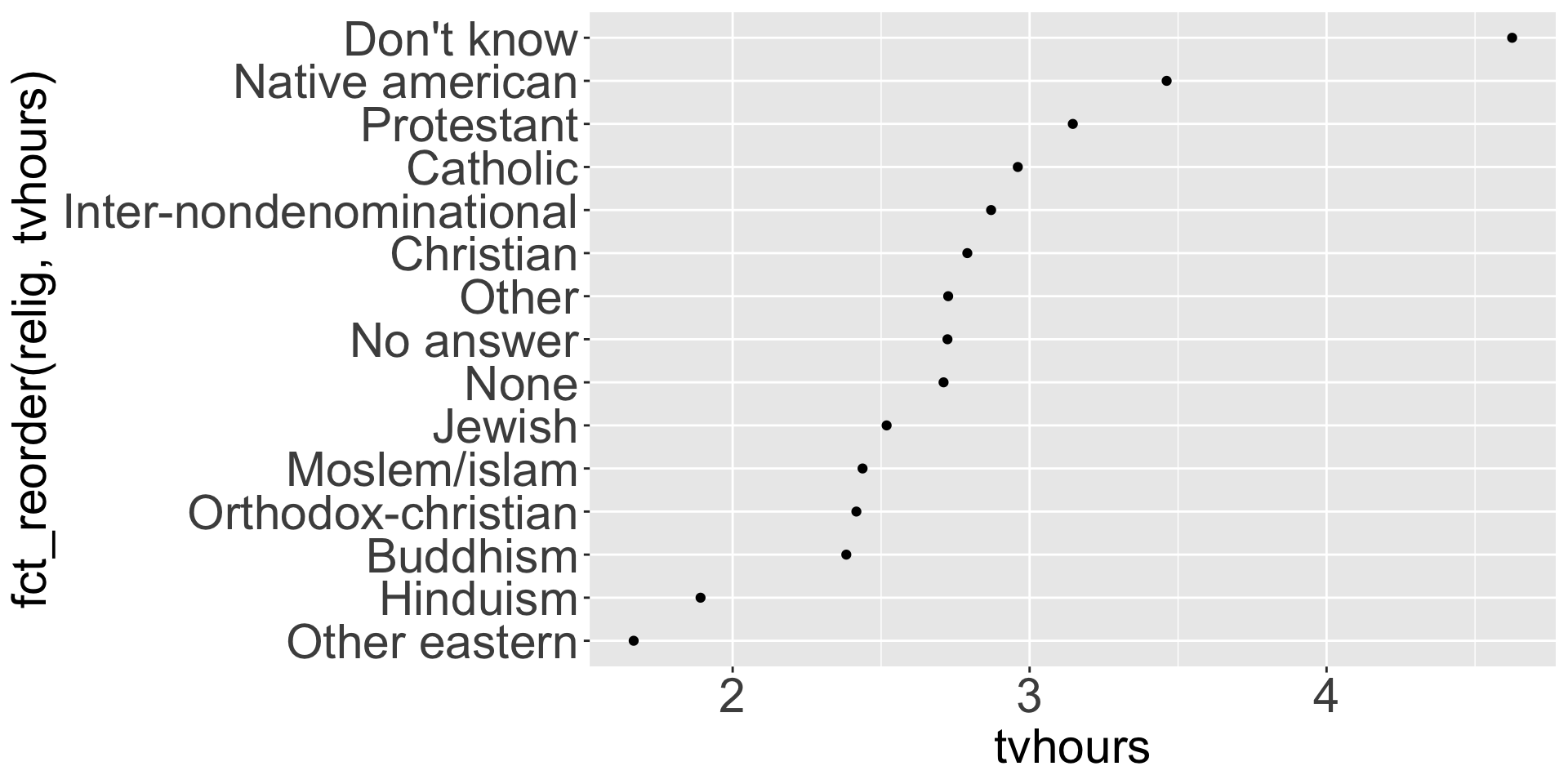
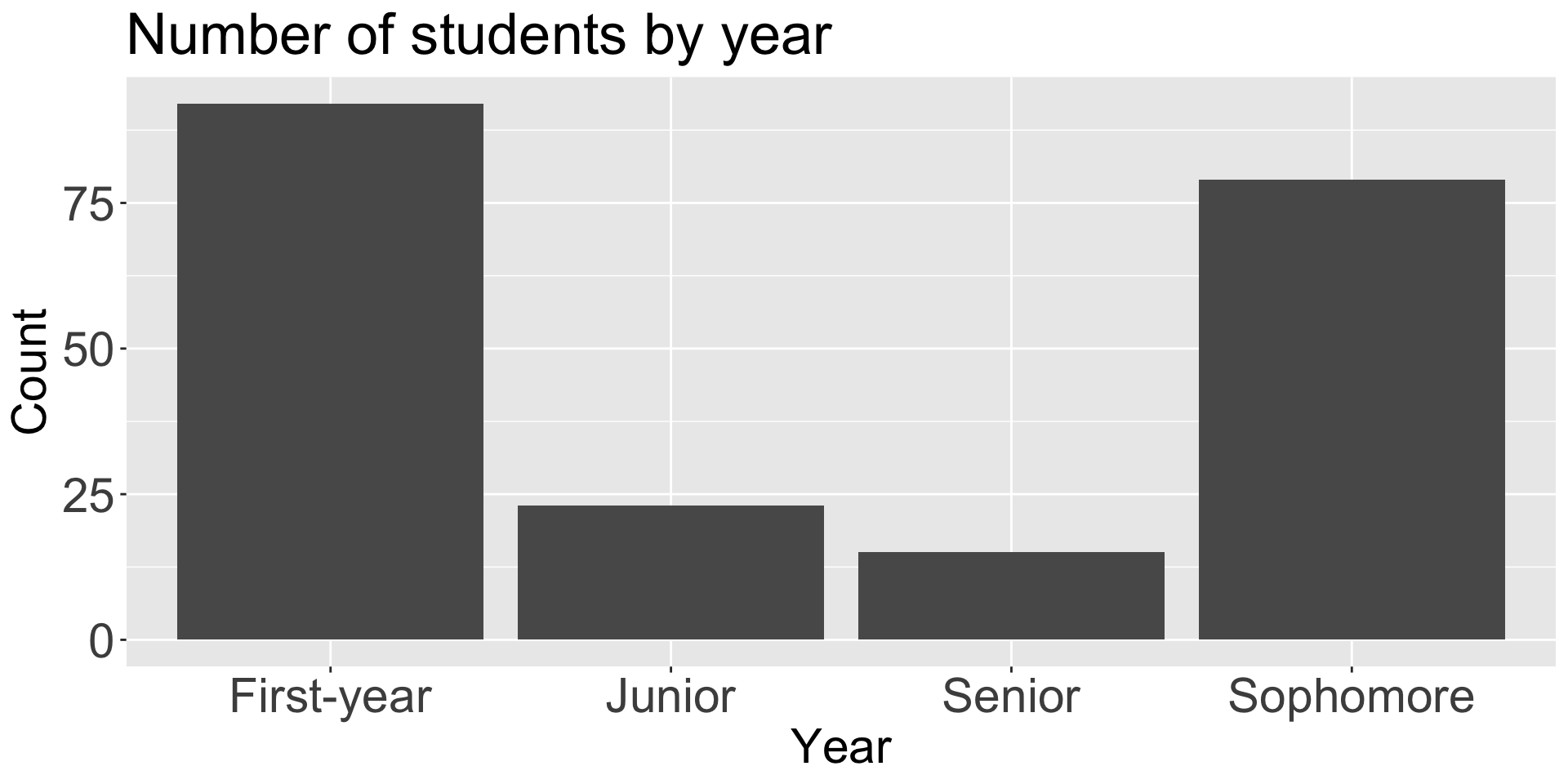
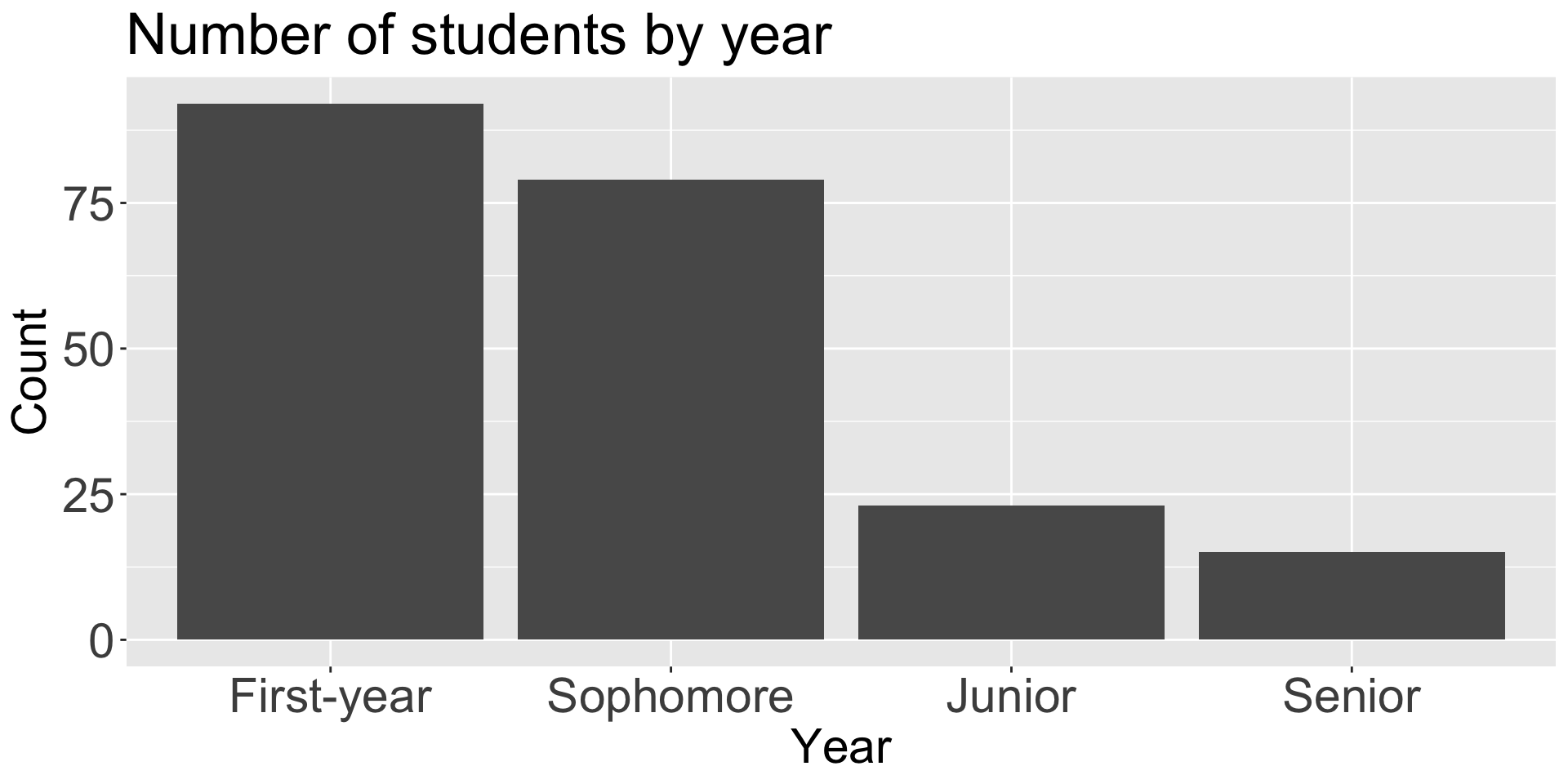
Factors are used for categorical variables, e.g., days of the week; religion; low, mid, high
Very helpful for ordering (i.e., when numerical and alphabetical ordering don’t cut it!)